Using Computer Vision to Detect Tables in PDFs
Contents
At work recently, I ran into a situation where the wonderful tabulizer package was just not picking up a table. I thinkt it was because the table was just text, and the cells were quite large, much like in the table below:
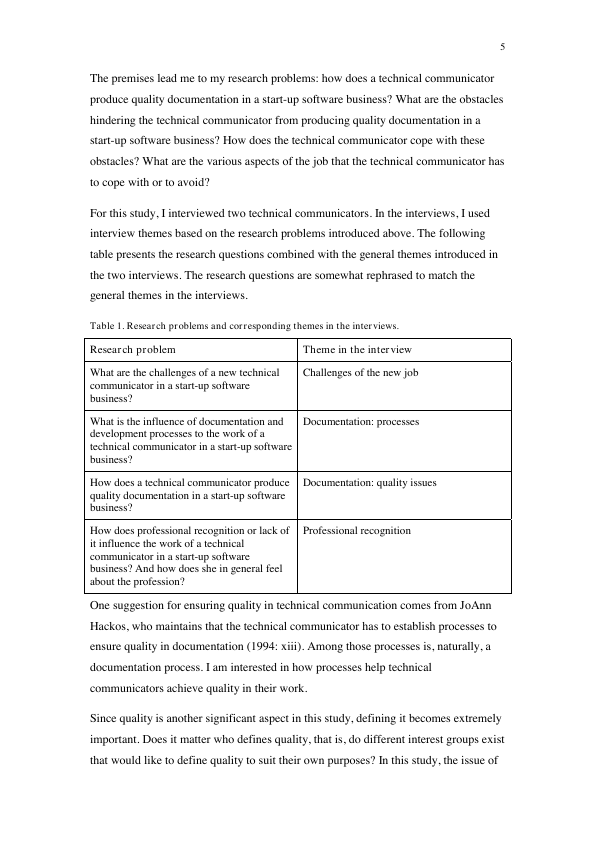
the full pdf can be found here
In order to get the text out in a reliable way, whle maintaining the table structure, I used a combination of the magick and imager packages in R, and the cv package in Python.
## setting up conda environment
library(reticulate)
library(here)## here() starts at /Users/samportnow/sam-portnow-website##
use_condaenv(here('envs'))
Sys.setenv(RETICULATE_PYTHON = here('envs', 'bin', 'python'))
reticulate::py_config()## python: /Users/samportnow/sam-portnow-website/envs/bin/python
## libpython: /Users/samportnow/sam-portnow-website/envs/lib/libpython3.7m.dylib
## pythonhome: /Users/samportnow/sam-portnow-website/envs:/Users/samportnow/sam-portnow-website/envs
## version: 3.7.5 (default, Oct 25 2019, 10:52:18) [Clang 4.0.1 (tags/RELEASE_401/final)]
## numpy: /Users/samportnow/sam-portnow-website/envs/lib/python3.7/site-packages/numpy
## numpy_version: 1.17.3
##
## NOTE: Python version was forced by RETICULATE_PYTHONknitr::opts_chunk$set(echo = TRUE)
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(pdftools)
library(stringr)
library(fs)
library(tesseract)
library(purrr)
library(magick)## Linking to ImageMagick 6.9.9.39
## Enabled features: cairo, fontconfig, freetype, lcms, pango, rsvg, webp
## Disabled features: fftw, ghostscript, x11library(imager)## Loading required package: magrittr##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names##
## Attaching package: 'imager'## The following object is masked from 'package:magrittr':
##
## add## The following object is masked from 'package:stringr':
##
## boundary## The following objects are masked from 'package:stats':
##
## convolve, spectrum## The following object is masked from 'package:graphics':
##
## frame## The following object is masked from 'package:base':
##
## save.imagelibrary(tidyr)##
## Attaching package: 'tidyr'## The following object is masked from 'package:imager':
##
## fill## The following object is masked from 'package:magrittr':
##
## extractThe first thing I’ll do is subset the pdf to the page I want. The code below is adapted from extracting many pages, so that’s why I refer to pages below.
fil = here('content', 'img', 'pdf_example.pdf')
fil_name = basename(fil)
# get just the pages you need
pages = 9
# put them all in split pdfs
walk(pages, ~ pdf_subset(fil, pages = ., output = here('content', 'img', 'split_pdfs',
paste0(fil_name, 'Page', ., '.PDF'))))
# now you have all the split_pdfs
pdfs = dir_ls(here('content', 'img', 'split_pdfs'))
# so you convert them to pngs
walk(pdfs, function(x){
filename = str_replace(x, 'split_pdfs', 'split_pngs')
filename = str_replace(filename, '\\.PDF', '\\.png')
pdf_convert(x, format = 'png', dpi = 72, filename = filename)
})Now that I have the pages I want turned into pngs, I can use computer vision to detect the borders. Again, here is the page I have:
import cv2
import numpy as np
import os
pngs = os.listdir('../img/split_pngs')[1]
# make sure we are only getting pngs
pngs = [p for p in pngs if 'png' in p]
for p in pngs:
print (p)
# read the image
img = cv2.imread('../../img/split_pngs/' + p)
# put it in grey scale
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
# look for borders
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.7*dst.max()]=[0,0,255]
img[dst<=0.7*dst.max()]=[0,0,0]
cv2.imwrite('../../img/borders/' + os.path.basename(p), img)And now we have the following png with the detected borders:
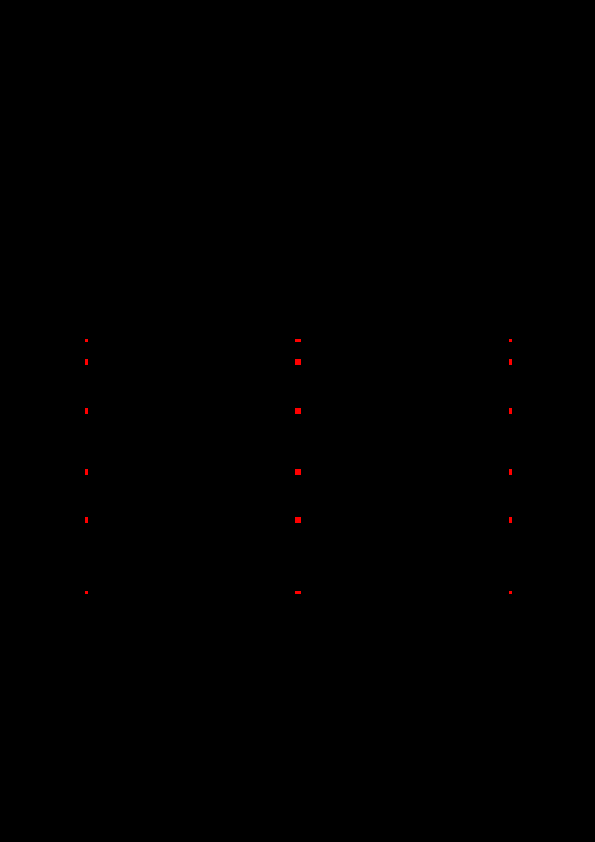
To extract the text, I am going to write a function that gets coordinates for the bounding boxes. To do this, for each point I detect, I get it’s corresponding “far point”, which I define as red pixels that are over 100 pixels away on the x axis and within a window of 5 pixels on the y axis. After detecting the far points, I simply making a bounding box out of them.
get_bounding_boxes = function(fil){
print (fil)
raw_img = load.image(fil)
img = as.data.frame(raw_img)
img = as_tibble(img)
# look for the red pixels
img = img %>% filter(cc == 1 & value == 1)
### from each x,y point get the closet far xy point
### were building lines here
img = img %>% arrange(x, y)
img$far_point = map2(img$x, img$y, function(x_pt, y_pt){
next_point = img %>% filter(x > x_pt + 50 & y < (y_pt + 5) & y > (y_pt - 5))
next_point = next_point %>% filter(x == min(x) & y == min(y))
c(next_point$x, next_point$y)
})
## if they didnt have a far point them drop them
img = img %>% filter(map_lgl(far_point, ~ length(.) > 0))
## break up x and y
img$far_x = map_dbl(img$far_point, ~.[1])
img$far_y = map_dbl(img$far_point, ~.[2])
img = img %>% distinct(far_x, far_y, .keep_all = T)
img = img %>% arrange(x)
if (nrow(img) < 2){
return(NA)
}
# x points are going to be from 1 - nrow(img) - 1, by 2, we're building boxes here
x_points = seq(1, nrow(img) - 1, by = 2)
boxes = map(x_points, function(x_pt){
tl = c(img[x_pt,]$x,img[x_pt,]$y)
tr = c(img[x_pt,]$far_x, img[x_pt,]$far_y)
bl = c(img[x_pt + 1,]$x, img[x_pt + 1,]$y)
br = c(img[x_pt + 1,]$far_x, img[x_pt + 1,]$far_y)
list('top_left' = tl,
'top_right' = tr,
'bottom_left' = bl,
'bottom_right' = br)
})
boxes
}fils_df = tibble(file_name = here('content', 'img', 'borders', 'pdf_example.pdfPage9.png'))
fils_df$bounding_boxes = map(fils_df$file_name, ~ get_bounding_boxes(.))## [1] "/Users/samportnow/sam-portnow-website/content/img/borders/pdf_example.pdfPage9.png"fils_df %>% str()## Classes 'tbl_df', 'tbl' and 'data.frame': 1 obs. of 2 variables:
## $ file_name : chr "/Users/samportnow/sam-portnow-website/content/img/borders/pdf_example.pdfPage9.png"
## $ bounding_boxes:List of 1
## ..$ :List of 10
## .. ..$ :List of 4
## .. .. ..$ top_left : int 86 340
## .. .. ..$ top_right : num 296 340
## .. .. ..$ bottom_left : int 86 360
## .. .. ..$ bottom_right: num 296 360
## .. ..$ :List of 4
## .. .. ..$ top_left : int 86 365
## .. .. ..$ top_right : num 296 361
## .. .. ..$ bottom_left : int 86 409
## .. .. ..$ bottom_right: num 296 409
## .. ..$ :List of 4
## .. .. ..$ top_left : int 86 414
## .. .. ..$ top_right : num 296 410
## .. .. ..$ bottom_left : int 86 470
## .. .. ..$ bottom_right: num 296 470
## .. ..$ :List of 4
## .. .. ..$ top_left : int 86 475
## .. .. ..$ top_right : num 296 471
## .. .. ..$ bottom_left : int 86 518
## .. .. ..$ bottom_right: num 296 518
## .. ..$ :List of 4
## .. .. ..$ top_left : int 86 523
## .. .. ..$ top_right : num 296 519
## .. .. ..$ bottom_left : int 86 592
## .. .. ..$ bottom_right: num 296 592
## .. ..$ :List of 4
## .. .. ..$ top_left : int 296 340
## .. .. ..$ top_right : num 510 340
## .. .. ..$ bottom_left : int 296 360
## .. .. ..$ bottom_right: num 510 360
## .. ..$ :List of 4
## .. .. ..$ top_left : int 296 365
## .. .. ..$ top_right : num 510 361
## .. .. ..$ bottom_left : int 296 409
## .. .. ..$ bottom_right: num 510 409
## .. ..$ :List of 4
## .. .. ..$ top_left : int 296 414
## .. .. ..$ top_right : num 510 410
## .. .. ..$ bottom_left : int 296 470
## .. .. ..$ bottom_right: num 510 470
## .. ..$ :List of 4
## .. .. ..$ top_left : int 296 475
## .. .. ..$ top_right : num 510 471
## .. .. ..$ bottom_left : int 296 518
## .. .. ..$ bottom_right: num 510 518
## .. ..$ :List of 4
## .. .. ..$ top_left : int 296 523
## .. .. ..$ top_right : num 510 519
## .. .. ..$ bottom_left : int 296 592
## .. .. ..$ bottom_right: num 510 592Now that I have the boxes, I want to convert my png to a high-res png. I am going to use ocr to extract the text, so I want to make sure the letters are crystal clear.
# now you have all the split_pdfs
pdfs = dir_ls(here('content', 'img', 'split_pdfs'))
# so you convert them to pngs
walk(pdfs, function(x){
filename = str_replace(x, 'split_pdfs', 'high_res')
filename = str_replace(filename, '\\.PDF', '\\.png')
pdf_convert(x, format = 'png', dpi = 1000, filename = filename)
})## Converting page 1 to /Users/samportnow/sam-portnow-website/content/img/high_res/pdf_example.pdfPage9.png... done!Now that I have the file in high res, I am going to write a function to crop the cells and ocr the text inside.
fils_df$high_res = dir_ls(here('content', 'img', 'high_res'))
cropped_text = map(1:nrow(fils_df), function(row){
boxes = fils_df[row,]$bounding_boxes[[1]]
if (is.null(boxes)){
return(NA)
}
if (length(boxes) == 1){
if (is.na(boxes)){
return (NA)
}
}
if (! file_exists(fils_df[row,]$high_res)){
return (NA)
}
original_img = image_read(fils_df[row,]$high_res)
crops = map(boxes, safely(function(x){
x_start = min(x$top_left[1], x$bottom_left[1]) * (1000/72)
x_end = max(x$top_left[1], x$top_right[1]) * (1000/72)
y_start = min(x$top_left[2], x$top_right[2]) * (1000/72)
y_end = max(x$bottom_left[2], x$bottom_right[2]) * (1000/72)
width = x_end - x_start
height = y_end - y_start
crop = paste0(width, 'x', height, '+', x_start, '+', y_start)
cropped = image_crop(original_img, crop)
(image_ocr(cropped))
}))
crops
})
fils_df$cell_text = map(cropped_text, ~ transpose(.)[['result']])And now we can take a look at what we got!
final_df = fils_df %>% unnest(cell_text)
final_df$cell_text = map_chr(final_df$cell_text, function(x){
ifelse(length(as.character(x)) == 0, NA_character_, as.character(x))
})
final_df$cell_text## [1] "Research problem\n"
## [2] "What are the challenges of a new technical\ncommunicator in a start-up software\nbusiness?\n"
## [3] "What is the influence of documentation and\ndevelopment processes to the work of a\ntechnical communicator in a start-up software\nbusiness?\n"
## [4] "How does a technical communicator produce\nquality documentation in a start-up software\nbusiness?\n"
## [5] "How does professional recognition or lack of\nit influence the work of a technical\ncommunicator in a start-up software\nbusiness? And how does she in general feel\nabout the profession?\n"
## [6] "Theme in the inter view\n"
## [7] "Challenges of the new job\n"
## [8] "Documentation: processes\n"
## [9] "Documentation: quality issues\n"
## [10] "Professional recognition\n"This is probably overkill for 99% of problems, but still pretty cool to play around with!
Author Sam Portnow
LastMod 2019-09-01